原文:Optimising the front end for the browser
笔记:涂鸦码龙
优化关乎速度和满意度。
- 从用户体验(UX)角度,我们希望前端网页可以快速加载
从开发体验(DX)角度,我们希望前端是快速,简洁,规范的
浏览器都做了什么
我们希望浏览器打开一个简单的网页
|
|
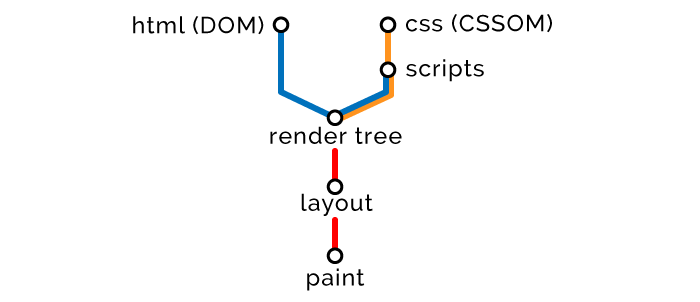
浏览器如何渲染网页
- 使用 HTML 创建文档对象模型(DOM)
- 使用 CSS 创建 CSS 对象模型(CSSOM)
- 基于 DOM 和 CSSOM 执行脚本(Scripts)
- 合并 DOM 和 CSSOM 形成渲染树(Render Tree)
- 使用渲染树布局(Layout)所有元素
- 渲染(Paint)所有元素
步骤一 — HTML
浏览器从上到下读取标签,把他们分解成节点,从而创建 DOM 。
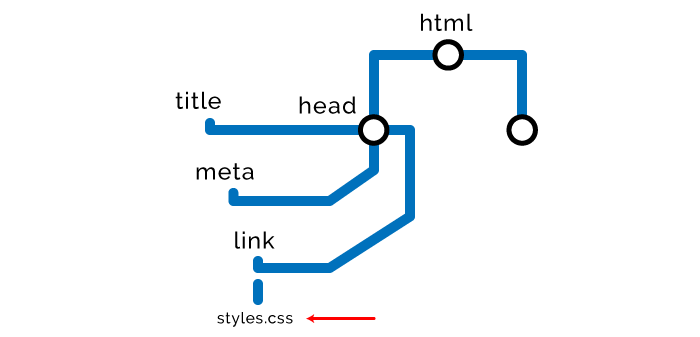
HTML 加载优化策略
- 样式在顶部,脚本在底部
总体思路是尽可能早的加载样式,尽可能晚的加载脚本。原因是脚本执行之前,需要 HTML 和 CSS 解析完成,因此,样式尽可能的往顶部放,当底部脚本开始执行之前,样式有足够的时间完成计算。
进一步讲讲如何优化
- 最小化和压缩
方法可用于所有内容,包括 HTML,CSS,JavaScript,图片和其它资源。
最小化是移除所有多余的字符,包括空格,注释,多余的分号,等等。
压缩比如 GZip,大大压缩下载文件的大小
两种方法都用的情况下,资源加载量减少了 80% 到 90%。比如:bootstrap 节省了 87% 的流量。
- 无障碍
不会提升页面的下载速度,但会大大提升残障人士的满意度。给元素加上 aria 标签,图片提供 alt 文本,HTML 5 无障碍参见。
使用诸如 WAVE 的工具鉴别哪些地方可以提高可访问性。
步骤二 — CSS
当浏览器发现任何与节点相关的样式时,比如:外部,内部,或行内样式,立即停止渲染 DOM ,并利用这些节点创建 CSSOM。这就是 CSS “渲染阻塞“ 的由来。这里是不同类型样式的优缺点。
|
|
CSSOM 节点创建与 DOM 节点创建类似,随后,两者合并如下:
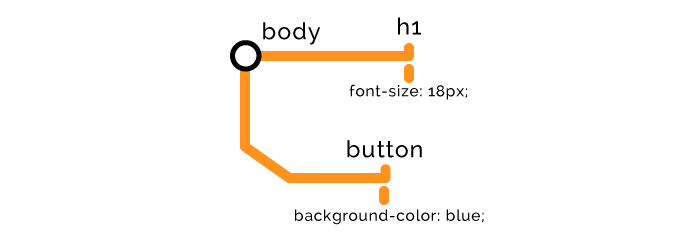
CSSOM 的构建会阻塞页面的渲染,因此我们想尽早加载样式,
CSS 加载优化策略
- 使用 media 属性
media 属性指定加载样式的条件,比如:符合最大或最小分辨率?还是面向屏幕阅读器?
- 延迟加载 CSS
有些样式,比如:首屏以下的,或者不那么重要的,可以等待首屏最有价值的内容渲染完成再加载,可以使用脚本等待页面加载,然后再插入样式。
这有两个栗子:The future of loading CSS,Defer load CSS
- 只加载需要的样式
使用 uncss 类似的工具,尽量移除不需要的样式。
步骤三 — JavaScript
浏览器不断构建 DOM / CSSOM 节点,直到发现外部或者行内的脚本。
由于脚本可能需要访问或操作之前的 HTML 或样式,我们必须等待它们构建完成。
因此浏览器必须停止解析节点,完成构建 CSSOM,执行脚本,然后再继续。这就是 JavaScript 被称作“解析器阻塞”的原因。
脚本只能等到先前的 CSS 节点构建完成。
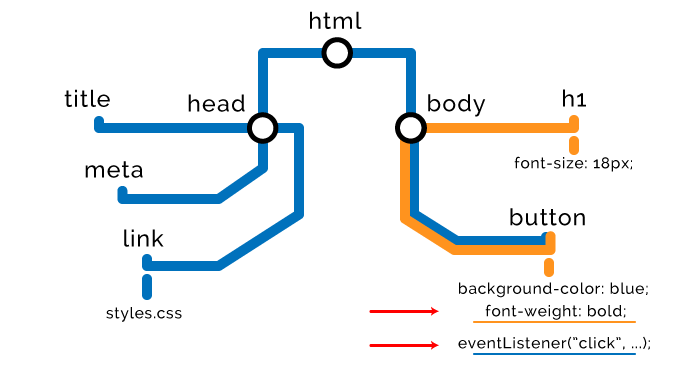
JavaScript 加载优化策略
- 异步加载脚本
脚本添加 async 属性,可以通知浏览器不要阻塞其余页面的加载,下载脚本处于较低的优先级。一旦下载完成,就可以执行。
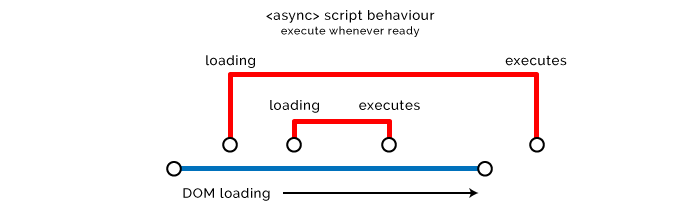
async 适用于不影响 DOM 或 CSSOM 的脚本,对一些跟我们的代码无关的,不影响用户体验的外部脚本尤其适用,比如:分析统计脚本。
- 延迟加载脚本
defer 跟 async 非常相似,不会阻塞页面加载,但会等到 HTML 完成解析后再执行。
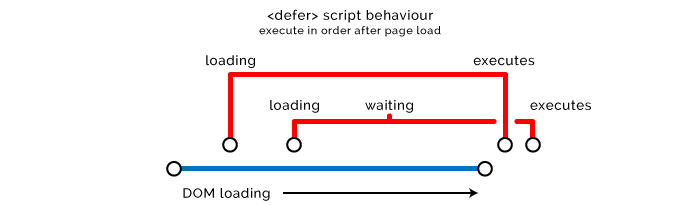
使用 defer 策略的 另一个好选择,或者也可以使用 addEventListener,了解更多,参加这里。
不幸的是 async 和 defer 对于行内的脚本不起作用,浏览器默认会编译执行它们。
- 操作之前克隆节点
多次操作 DOM 时可以尝试,首先克隆整个 DOM 节点更加高效,操作克隆后的节点,然后替换先前的节点,避免了多次重绘,降低了 CPU 和内存消耗,同时也避免了不必要的页面闪烁。
需要注意,克隆的时候并没有克隆事件监听。
- Preload/Prefetch/Prerender/Preconnect
这些新属性并不是所有的浏览器都支持。了解详情可以看这里:Prefetching, preloading, prebrowsing
步骤四 — 渲染树(Render Tree)
一旦所有节点已被解析,DOM 和 CSSOM 准备合并,浏览器便会构建渲染树。如果我们把节点想象成单词,那么对象模型就是句子,渲染树便是整个页面。
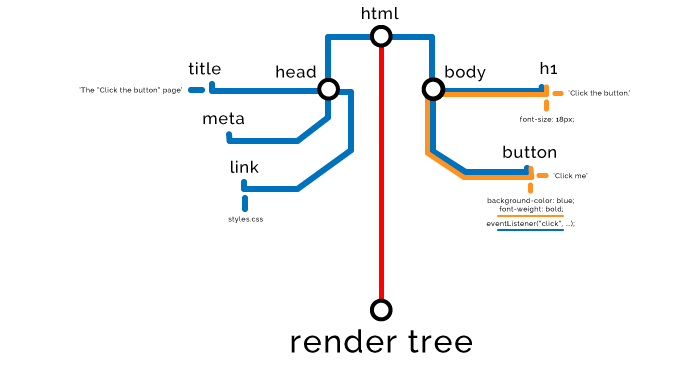
步骤五 — 布局(Layout)
布局阶段需要确定页面上所有元素的大小和位置。
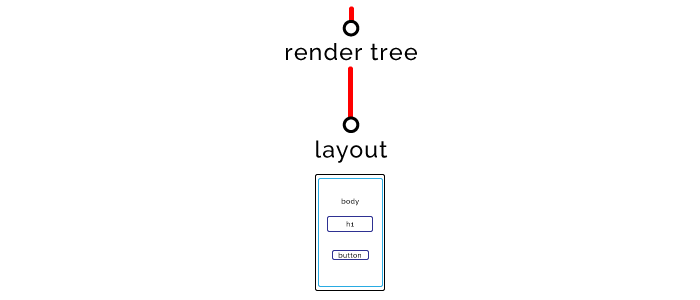
步骤六 — 渲染(Paint)
最终的渲染阶段,会真正地光栅化屏幕上的像素,把页面呈现给用户。
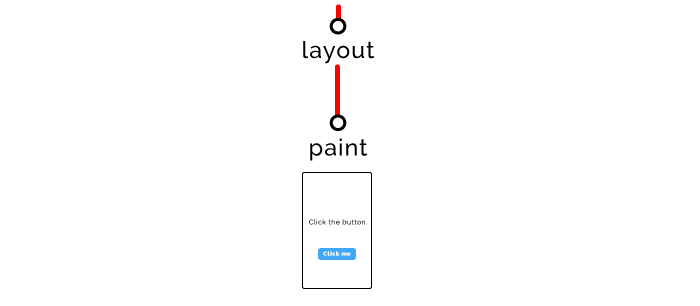
整个过程耗时1秒或十分之一秒,我们的任务是让它更快。
如果 JavaScript 事件改变了页面的某部分,便会引起渲染树的重绘,并且迫使布局(Layout)和渲染(Paint)过程再次进行。
浏览器如何发起网络请求
当浏览器请求一个 URL,服务端会响应一些 HTML。
我们需要认识一个新术语,关键渲染路径(Critical Rendering Path (CRP)),就是浏览器渲染页面的步骤数,如下图。
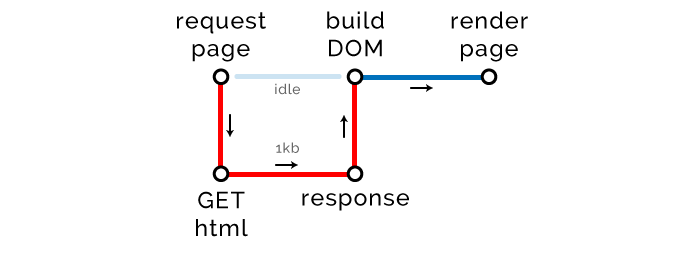
关键路径长度
关键渲染路径的度量标准是路径长度。最理想的关键路径长度是1。
如果页面包含一些内部样式和 JavaScript ,关键路径发生以下改变。
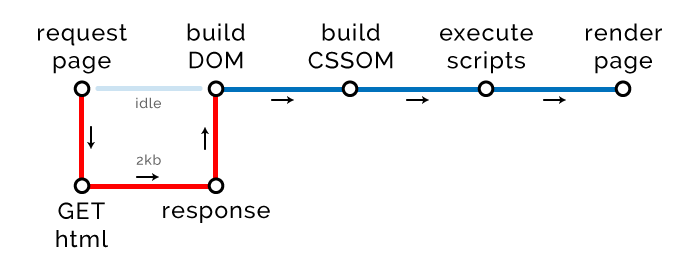
新增两步,构建 CSSOM和执行脚本,因为我们的 HTML 有内部样式和脚本需要计算。由于没有外部请求,我们的关键路径长度没变。
但是注意,我们的 HTML 大小增加到了 2kb,某些地方还是受了影响。
关键字节数
三个度量标准之二出现了,关键字节数,它用来衡量渲染页面需要传送多少字节数。
如果你认为不需要外部资源,就大错特错了,外部资源可以被缓存。
我们使用一个外部 CSS 文件,一个外部 JavaScript 文件,和一个外部带 async 属性的 JavaScript 文件。关键路径图如下:
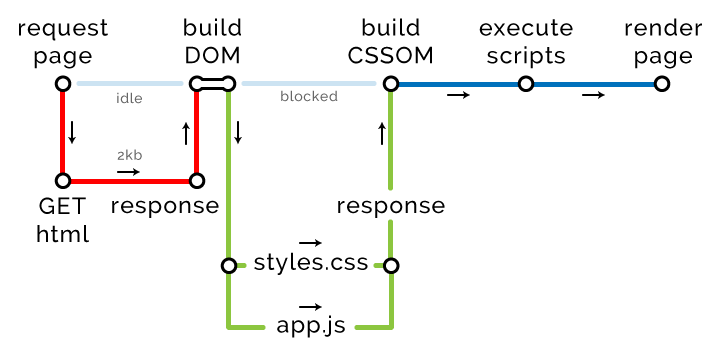
浏览器请求页面,构建 DOM,发现外部资源后开始下载,CSS 和 JavaScript 有较高的优先级,其它资源次之。
styles.css 和 app.js 通过另一个关键路径获取。暂时不获取 analytics.js ,因为加了 async 属性,浏览器将用另一个线程下载它,它处于较低优先级,不会阻塞页面渲染,也不影响关键路径。
关键文件
最后一个度量标准是关键文件,浏览器渲染页面需要下载的文件总量。以上例子,HTML 文件,CSS 和 JavaScript 文件算关键文件,async 的脚本不算。当然是文件越少越好。
回到关键路径长度
以上例子就是最长的渲染路径吗?我认为渲染页面时,我们仅需要下载 HTML,CSS 和 JavaScript 文件,仅通过两次服务器往返就做到了。
HTTP1 文件限制
我们浏览器的 HTTP1 协议,在同一个域名,同一次,允许下载的文件数有最大限制,范围从 2(老旧的浏览器)到 6(Edge,Chrome)。
各种浏览器请求文件的最大并发数,参见Maximum concurrent connections to the same domain for browsers。
通过把一些资源存放到影子域名,可以绕过这个限制,以达到最佳优化效果。
注意:不要把关键的 CSS 放到根域名之外的其他域名,有些场景下会对 DNS 查找和延迟起反作用。
HTTP2
如果网站使用了 HTTP2,并且用户的浏览器也兼容,则可以完全避开这个下载限制。
这里有个 HTTP2 测试网站。
TCP 往返限制
每一次服务器往返可以传送的最大数据量是 14kb,包括所有 HTML,CSS 和脚本的网络请求。
如果我们的 HTML,或者积累的资源请求超过 14kb时,需要多做一次服务器往返。
大魔法师
我们整个 HTML 页面可以很好的压缩, GZip 可以压缩到 2kb,远低于 14kb 的限制,因此,一次服务器往返就可以搞定。
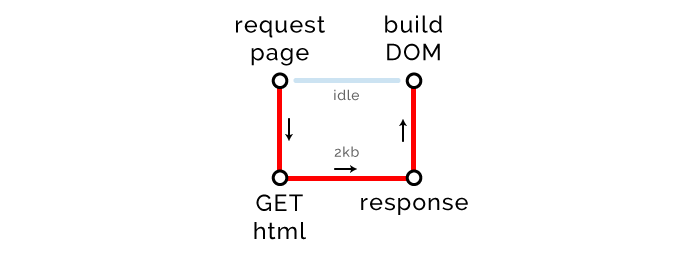
关键路径度量: 长度 1,文件数 1,字节数 2kb
浏览器发现外部资源(CSS 和 JavaScript)时,发起请求开始下载它们。首要下载的 CSS 文件是 14kb,达到了往返传输的最大限制,因此增加了一条关键路径。
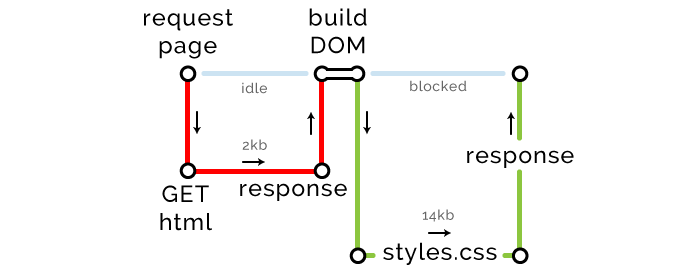
关键路径度量: 长度 2,文件数 2,字节数 16kb
余下的资源低于 14kb,但是总共有 7 个资源,由于网站未启用 HTTP2,我们的 Chrome,每一次往返仅可以下载 6 个文件。
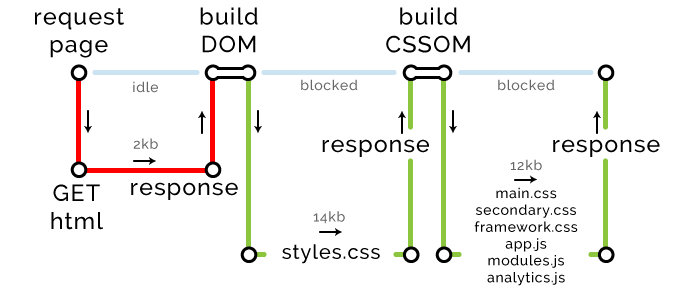
关键路径度量: 长度 3,文件数 8,字节数 28kb
下载完最终文件,并开始渲染 DOM。
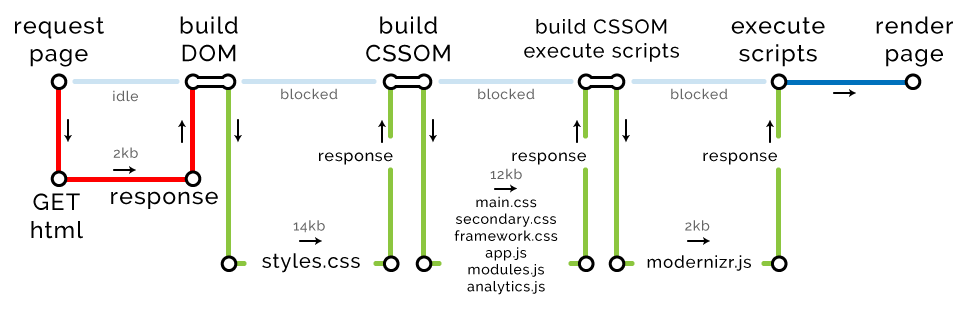
关键路径度量: 长度 4,文件数 9,字节数 30kb
基于以上的信息和知识,发起每个连接时,就可以准确地预估页面的性能了。
浏览器网络优化策略
- Pagespeed Insights
使用 Insights 鉴别性能问题,Chrome DevTools 也有个 audit 标签。
- 充分利用 Chrome 开发者工具
这篇文章 值得一读,帮你理解网络资源
- 在优质的环境里开发,在艰苦的环境里测试
开发时大可使用 1Tb SSD,32G 内存的 Macbook Pro ,但是性能测试时还是要到 Chrome 的 network 标签下模拟低带宽的情形,从而获取有价值的信息。
- 合并资源/文件
基本上,每接收到一个外部 CSS 和 JavaScript 文件,浏览器都会构建 CSSOM,执行脚本。尽管几个文件可以在一次往返中传送,但也浪费了浏览器的宝贵时间和资源,最好还是合并文件,减少不必要的加载。
- 首屏内容使用内部样式
内部 CSS 和 JavaScript 不需要请求外部资源,相反,外部资源又可以被缓存,并保持 DOM 轻量,两者没有非黑即白。
但是一个非常好的论点是首屏关键内容使用内部样式,可以避免请求额外的资源,节省时间做最有意义的渲染。
最小化/压缩图片
延迟加载图片
异步记载字体
是否真正需要 JavaScript / CSS?
原生 HTML 元素可以实现的行为是否用了脚本?是否有样式或者图标可以行内创建的,不需要内部/外部资源?比如:行内 SVG。
- CDN
可以利用 CDN(内容分发网络)存储资源,它会从离用户最近,延迟最低的位置分发到用户设备,加载时间更快。
延伸阅读
综述
关键渲染路径是最重要的,它使得网站优化有规律可循。需要关注3个指标:
1—关键字节数
2—关键文件数
3—关键路径长度
原文:Optimising the front end for the browser
笔记:涂鸦码龙
优化关乎速度和满意度。
- 从用户体验(UX)角度,我们希望前端网页可以快速加载
从开发体验(DX)角度,我们希望前端是快速,简洁,规范的
浏览器都做了什么
我们希望浏览器打开一个简单的网页
|
|
浏览器如何渲染网页
- 使用 HTML 创建文档对象模型(DOM)
- 使用 CSS 创建 CSS 对象模型(CSSOM)
- 基于 DOM 和 CSSOM 执行脚本(Scripts)
- 合并 DOM 和 CSSOM 形成渲染树(Render Tree)
- 使用渲染树布局(Layout)所有元素
- 渲染(Paint)所有元素